![Icon of a CSV file with a pencil, indicating a file used for entering or editing comma-separated values. The icon is designed to resemble a physical document with lines of text and the CSV extension in the upper right corner, encapsulated in a blue rounded square with a slight shadow effect.]() CSV, or files with “comma separated values”, is a simple format that everyone should be able to handle. Certainly you’d think so except nothing is ever that straightforward and if you’ve ever spent time trying to work with these files and having to deal with all the problems inherent to this format then you’ll know exactly what I’m talking about. In our industry, localization, the number of problems can even increase because we also have to deal with converting the content from one language to another. I also wondered if there is a standard for CSV and the closest things to one is more of a recommendation, called RFC 4180. It doesn’t seem to have been updated since 2005 and doesn’t take account of many of the problems that can be caused by not managing these files carefully.
CSV, or files with “comma separated values”, is a simple format that everyone should be able to handle. Certainly you’d think so except nothing is ever that straightforward and if you’ve ever spent time trying to work with these files and having to deal with all the problems inherent to this format then you’ll know exactly what I’m talking about. In our industry, localization, the number of problems can even increase because we also have to deal with converting the content from one language to another. I also wondered if there is a standard for CSV and the closest things to one is more of a recommendation, called RFC 4180. It doesn’t seem to have been updated since 2005 and doesn’t take account of many of the problems that can be caused by not managing these files carefully.
So what sort of things are we talking about? Here’s a few…
Character Encoding Issues
I have discussed this at length in the past, but CSV files can be saved in different character encodings, such as UTF-8 or ISO-8859-7 for example. The only problem is that with the exception of UTF-8 with a BOM (Byte Order Mark), when you send that file to someone else and don’t tell them what encoding you used they will have no way of knowing and this could result in characters becoming corrupted resulting in an inability to read them any longer and possibly cause problems on import to their intended application after the translation is complete. For example if I open a CSV containing Greek characters in notepad I see this as it defaulted to an encoding called Win-1252:
![A screenshot showing a table with corrupted text. The table appears to have four columns labeled TransactionID, Date, Amount, and Description. The rows contain dates in the format YYYY-MM-DD, Euro amounts, and descriptions with garbled text, which includes various special characters and diacritics in a pattern that suggests a text encoding issue.]()
Had I known the intention in this case was to use ISO-8859-7 Greek (ISO) for an old legacy system then I would have made sure to use this when handling the file to make sure it’s handled and returned with the same encoding.
Some tools can take a guess at the encoding using heuristics or defaults to guess the encoding, but this process is not foolproof. It can lead to misinterpretation of the file’s content, especially if it contains characters outside the ASCII range. For example, I have started using an application called Rons Data Edit for working with files like this (it used to be called Rons CSV Editor many years ago when I first used it and I almost forgot I had it until it was updated recently) and this version of the application is so good (in my opinion) it’s now my default application for these sort of files. There are many reasons why I like this, but I’ll try and share a few reasons as we go along. The first reason would be that I can set a fallback encoding for files I’m working on if it cannot be recognised as UTF-8 for example:
![Screenshot of a computer interface with a CSV file named "greek.csv" open, showing a table with headers "TransactionID", "Ημερομηνία" (Date), "Ποσό" (Amount), "Περιγραφή" (Description), "Κωδικός Συναλλαγής" (Transaction Code), and "Λογαριασμός Προορισμού" (Destination Account), with sample data in Greek. A settings window overlay with "Data Edit Options" is open, showing "Text Defaults" section with "Encoding" set to "ISO-8859-7 - Greek (ISO)" and "Line Separator" set to "New Line". Red arrows point to the encoding and line separator settings.]()
You can also see the next reason I like this software is because not only has the file opened up using ISO-8859-7 Greek (ISO), but it’s also nice and clear so I can easily read it. You may say you can do this in Excel, and you can, but I can’t tell you how many times I’ve seen Excel mess up CSV files, and how many times I’ve seen people messing them up because they don’t know how to work properly with a CSV in Excel. In Rons Data Edit it’s simple, you just open them!
Now some of you may be thinking, don’t talk crap Paul since UTF-8 can be used to handle everything these days. This is mostly true, but it’s also fair to say that several other encodings are still commonly used today, especially in legacy systems or in regions with specific language requirements. For example. I think these are still relatively commonplace:
- ISO-8859 Series: There are several variations catering to different languages, such as ISO-8859-1 (Latin-1 for Western European languages), ISO-8859-2 (Latin-2 for Central and Eastern European languages), and others in this series.
- Windows-1252: Often used by default in older Windows systems, it’s similar to ISO-8859-1 but includes additional printable characters.
- Shift JIS: Can still be used for Japanese text, especially on platforms where legacy support is needed.
- GB2312 and GBK: Encodings for Simplified Chinese characters, used in Mainland China.
- BIG5: An encoding for Traditional Chinese, used primarily in Taiwan and Hong Kong.
- KOI8-R and KOI8-U: Used for Russian and Ukrainian respectively, particularly in older systems.
- EUC Family: Including EUC-JP for Japanese, EUC-KR for Korean, and others for various Asian languages.
These encodings are often maintained for compatibility with older systems, for certain governmental regulations, or in user communities where these encodings remain standard. However, it’s definitely true that the global computing community continues to adopt Unicode (and UTF-8 by extension) due to its ability to handle virtually all text in any language, and all the crazy emojis for example that we see today, through a single encoding system. So having a decent editor to help with these files is something worth investing in if you work in a profession that is forced to handle them from time to time.
The takeaway from here would be to always ask your client what encoding should be used if they don’t tell you; and then make sure you have the appropriate tooling to handle them without breaking them.
Delimiter Confusion
The term “CSV” suggests that commas are used as field separators. However, the delimiter can vary by region and use. Here’s a few common ones you may have come across before:
- TSV (Tab-Separated Values)
- PSV (Pipe-Separated Values)
- SCSV (Semicolon-Separated Values)
- SSV (Space-Separated Values)
- Custom Delimiter-Separated Values
This can lead to confusion when opening a file in software that expects a different delimiter. If you’re using Excel you need to make sure you specify the delimiter before importing the data… if you use Rons Data Edit it recognises most separators out of the box, but you can also set up a data profile to handle anything you like:
![Screenshot of a software interface for editing data profiles. The 'Edit Data Profile' pane is active, showing settings for a 'Semi-Colon Separated' profile. Fields include 'Name', 'Field Open' and 'Close' with quotation marks, 'Field Separate' with a semicolon, and 'First Row is Header' checked. Under 'File Details', 'Use as File format' and 'Associate File' are checked with 'File Extension(s)' set to csv. There's a navigation bar with options like 'Add', 'Delete', and 'Save File'.]()
We are not the only ones getting confused. I’ve had a fruitless engagement with the Deutsche Bank on and off for years who don’t seem able to export a properly formatted CSV for import into an accounting application. Every month I have to correct the file before I can import it because they don’t wrap fields containing a semi-colon as part of the text in a SCSV (Semicolon-Separated Values) export file. So for example they give me a file like this:
Booking date;Value date;Transaction Type;Beneficiary / Originator;Payment Details;Debit;Credit;Currency
08/08/2023;08/08/2023;Debit Card Payment;DM Fil.;DM FIL.2490 H:65349;-22.40;;EUR
08/08/2023;08/08/2023;SEPA-Direct Debit;Vollkorn Naturkost;Kundenkarte 1234;Rabattabzug erfolgt immer zum Monatsende;Danke - Ihr BioMarkt;-76.35;;EUR
08/09/2023;08/09/2023;Debit Card Payment;Edeka;EDEKA KOEHLER;-22.83;;EUR
08/09/2023;08/09/2023;Debit Card Payment;Alnatura;ALNATURA PRODUKTIONS;-37.71;;EUR
When I open it in my editor it looks something like this:
![Screenshot of a CSV file named "misalign.csv" displayed in a table format. The headers include "Booking date", "Value date", "Transaction Type", "Beneficiary / Originator", "Payment Details", "Debit", "Credit", and "Currency". Row 2 is highlighted, showing a misalignment where "Debit" column entry "-76.35 EUR" shifts into the "Currency" column.]()
Note that Row 2 is completely misaligned. This is easily spotted in this editor, but in an ordinary text editor you can see how complicated it can get to spot that it should have been written like this:
Booking date;Value date;Transaction Type;Beneficiary / Originator;Payment Details;Debit;Credit;Currency
08/08/2023;08/08/2023;Debit Card Payment;DM Fil.;DM FIL.2490 H:65349;-22.40;;EUR
08/08/2023;08/08/2023;SEPA-Direct Debit;Vollkorn Naturkost;"Kundenkarte 1234;Rabattabzug erfolgt immer zum Monatsende;Danke - Ihr BioMarkt";-76.35;;EUR
08/09/2023;08/09/2023;Debit Card Payment;Edeka;EDEKA KOEHLER;-22.83;;EUR
08/09/2023;08/09/2023;Debit Card Payment;Alnatura;ALNATURA PRODUKTIONS;-37.71;;EUR
Very hard to spot… and another point worth noting with quotes used to wrap a column… make sure they are straight quotes because otherwise they just become text within the field.
Lack of Standardization for Encoding Complex Types
While basic data types (strings, numbers) are straightforward to encode in CSV, more complex types (dates, boolean values) can be represented in multiple ways, leading to inconsistencies. For example, dates might be formatted differently depending on the locale. Why is this a problem? Perhaps take a look at the CSV I used as an example from my bank. The dates are 08/08/2023, and 08/09/2023. In this format I have no idea whether this is dd/mm/yyyy or mm/dd/yyyy. In my bank export it’s obviously not a problem as I know by now and after I get past the 12th day it all comes clear, but for a long file provided for translation with thousands of lines and dates it could be a problem if you need to make sure a particular format is used in the translation and it’s not the same as the source.
There’s not a lot you can really do if your client doesn’t tell you what format the dates are in and every date happens to be a day that never exceeds the 12th of the month! But Rons Data Edit has a few neat tricks that you probably won’t find in Excel and could be very helpful. For example, if the source locale is en(US) I can pretty much expect the dates to be mm/dd/yyyyy. I can check this and I might find any incorrect dates in the source before I start which can help with the validation of the target later:
![A 'Filter' panel is in Rons Data Edit showing a filter condition that 'Booking date' is not a matching the condition. The condition is English (United States).]()
- create a filter to use the column with the date in it and set it to either find what you want, or what you don’t want. In this case I set it to find the dates that don’t match the date in my options.
- the option I used was the “Conversion Region” which is English (United States). I’m assuming this is being drawn from my windows regional settings since there are no controls over the settings for the local in Rons Data Edit itself, and here I use mm/dd/yyyy for the en(US) date.
- after applying the filter I see the one date in this small example that doesn’t match the required format.
Pretty neat and I’m mentioning it because I haven’t come across a feature like that in a text editor before. But the other good capability is that it also supports regular expressions which you don’t get with Excel. This is incredibly useful for a couple of reasons:
- I can carry out some basic data validation on the source and these can be saved as a construct I can reuse. Getting the source right should make the localization process easier with less errors.
- I can search replace content in the source to ensure I maximise the leverage from my TM by improving placeable recognition, and again reduce errors in the target translation.
The search & replace should be familiar to us all as it’s fairly similar to Trados Studio with the exception it shows the change in real time and highlights them in the document… something I wish Trados Studio could do too ![😉]()
![Search & Replace functionality using regular expressions in Rons Data Edit shoing the result in real time and highlighted in a different colour.]()
Newline Characters Within Fields
Handling newline characters within fields can be problematic. Different systems may expect different newline conventions (LF vs. CRLF for example), and improperly handled newlines within fields can be interpreted as new records, leading to data corruption. In all cases we want to be able to manage the files so we send them back to the client in the same way they were received. Here’s a simple example in my normal text editor:
![Multiline CSV opening in a text editor showing the mixed Line Feeds and Carriage Returns within the file.]()
Mixing LF with CRLF in one file should probably not really happen, but it can simply because of the way these types of files get handled. Typically Windows uses a Carriage Return followed by a Line Feed (CRLF, \r\n) as the EOL (End of Line) marker. Unix/Linux use a Line Feed (LF, \n) and when using a MAC the older versions (Mac OS 9 and earlier) used a Carriage Return (CR, \r) whilst Mac OS X and later versions adopted the Unix standard of LF (\n).
When translating these files you should try to ensure that you don’t change these EOL markers so that you avoid any unexpected behaviour when the files are returned to the application they originated from. This of course begs the question why should they change? Well, a number of ways ranging from curious opening and closing files intended for Windows in a Mac just to see what they look like for example, to manipulating them in tools not designed to maintain their integrity like Excel. Expanding on the use of Excel, if I open this file in my example by importing them (I won’t go into just plain opening them which is another mistake people often make) I see a couple of problems. The first is that the markers seem to have disappeared altogether:
![The same CSV file opened in Excel and showing no breaks between the lines that should be on seperate lines in each cell.]()
In practice, saving this file back to CSV doesn’t remove the EOL markers, but if you were to handle the file in Excel itself you could easily break this since you don’t know the EOL marker is there at all. You might add the spaces between the sentences for example and lose the marker. But what does happen when you resave the file as CSV, is that Excel replaces these EOL markers with a pilcrow like this:
![CSV resulting from beings saved in Excel and the CRF and LF EOL markers are all replaced with a Pilcrow.]()
A pilcrow isn’t really an EOL marker and it’s more a function of text processing and document editing software than of operating systems themselves. I’d also like to think that modern systems these days will most likely cope and make sense of the structure of the file even if you do send it back with these changes to the original. But the wisest approach is always going to be to maintain the integrity of the source file you received and provide the translation in the exact same way it was presented to you. And for that you need a tool that won’t mess it up. Notwithstanding that when I open this file in Rons Data Editor it’s perfect ![😉]()
![Screen hot of Rons Data Editor shoing the multiline CSV rendered clearly and without problems.]()
If you hadn’t realised yet I like this tool!
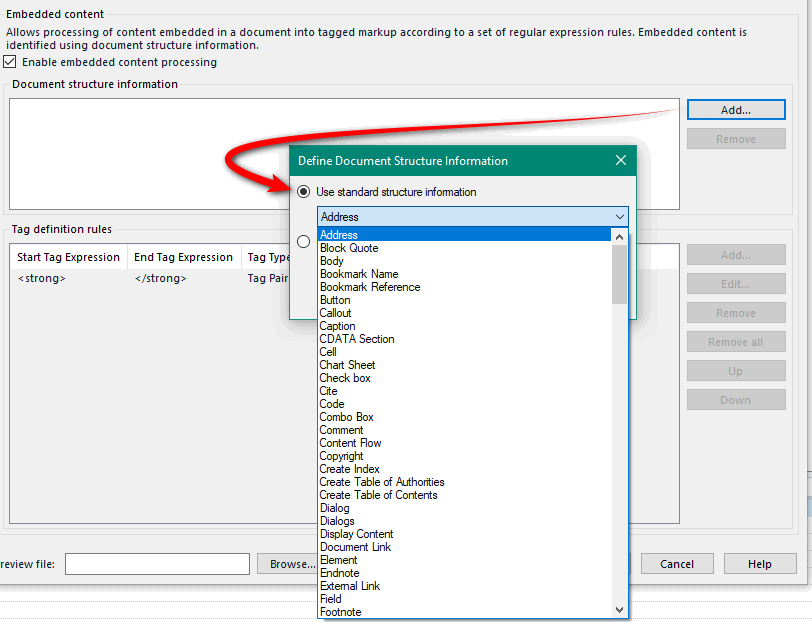
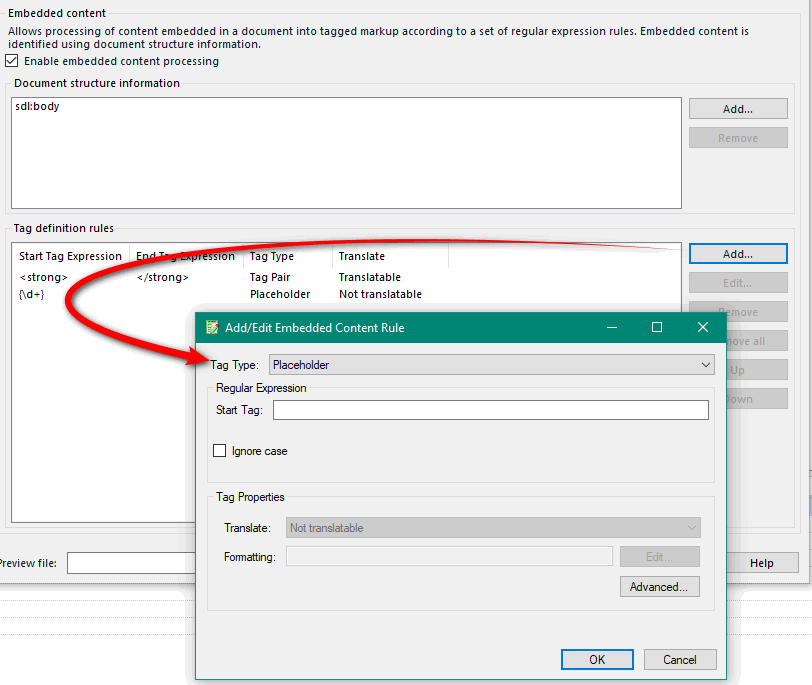
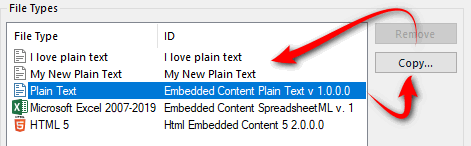
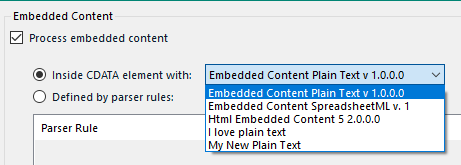
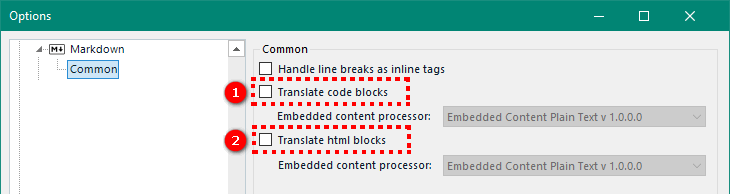
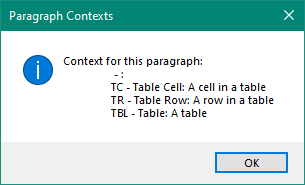
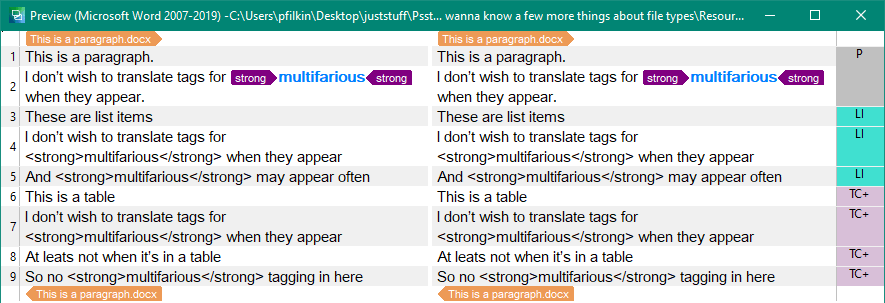
Embedded Content
Whilst there are more things that can go wrong with a CSV I probably covered the main things already, with the exception of handling embedded content, for problems associated with translation. Embedded content is a topic that comes up again and again in the forums as people look for a way to handle the markup so it’s safely protected. For example, take this simple example file:
ID,Name,Description,Category,Last Updated
201,LED Lamp,<p>Energy-efficient LED lamp with <strong>adjustable brightness</strong>. Perfect for desks and bedside tables.</p>,Home & Office,2024-01-15
202,Water Bottle,"<p>Durable, leak-proof <strong>water bottle</strong>. BPA-free plastic. <a href='https://example.com'>Buy now</a>.</p>",Sports & Outdoors,2024-01-10
203,Backpack,<p>Lightweight backpack with multiple compartments. Ideal for travel and <em>everyday use</em>.</p>,Travel & Luggage,2024-01-20
Many CSV files that contain embedded content can be difficult to read with the combination of delimiters and markup creating a quite confusing environment for understanding the structure of the file itself. If I open it in Rons Data Editor I can not only see a very clear structure for the fields but in this case I note it also has a very neat HTML viewer built into it:
![Rons Data Edit showing embedded content displayed as rendered HTML so it's easy to read.]()
This isn’t going to help you handle the markup in Trados Studio but it is surely a help for when you come to proofread the file. Now you can read the text without the tags being in the way and you can double check correctness of the tags based on the html rendering of your work.
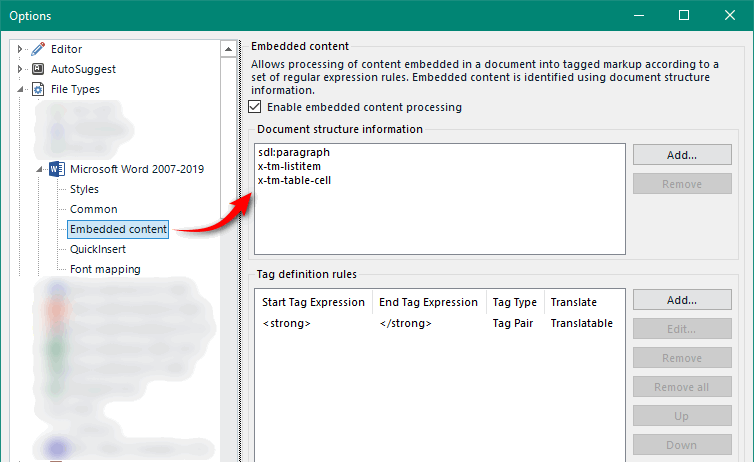
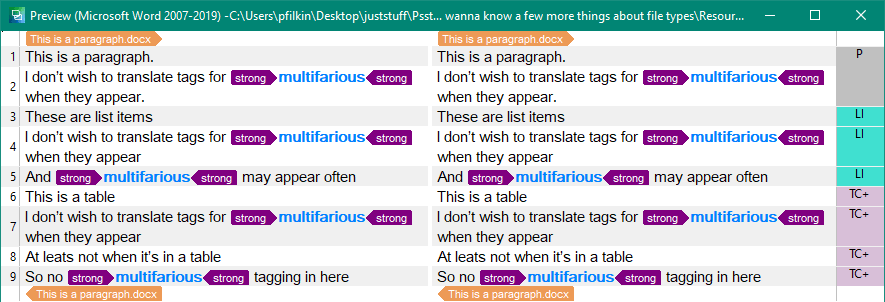
I’ve covered embedded content many times in my blog but the closest filetype to this in terms of how to manage it would addressed in this article about handling taggy files in Excel. It still uses the old regex only approach which is what you’ll also find in the CSV filetype so that article should get you to where you need to be.
But what about Trados Studio?
I’ve spent a good while now talking about CSV files and Rons Data Edit, and I’ve really only scratched the surface of what this tool is capable of doing. But even with the smaller usecase I have for working with these files I think it’s become an invaluable tool in my toolbox. The developer is also really helpful and regularly updates the application, so if you’re looking for a better way to help you work with these files you couldn’t do much better based on the experience I’ve been having so far.
But what about Trados Studio? Well now that we know everything we probably need to know about CSV files this bit is simple!! We’re not going to look at conversions to Excel to do this, we’ll look at a real example, a simple one, that I came across last week. In the RWS Community ideas page for Trados Studio I saw a request from a couple of users to be able to translate the file and folder names for a project based on a nested folder. My initial reaction to this was surprise, and I have to confess I’m still surprised, as this surely creates work, and room for problems, especially if the files themselves contain any references to the folders or other files within them. It seems such a rare requirement to me and one much better managed through a little engineering afterwards. I also like to dabble in scripting these days now that we have AI to help so much so to do this I created two powershell scripts.
Script #1: Create a tab separated file
If you want to try it copy the code and save it to a file with the extension ps1. So I called this 01_extract.ps1 for example:
$rootFolder = Read-Host "Enter the path of the root folder"
$outputFile = ".\filelist.txt"
function Get-FileFolderList($path) {
Get-ChildItem -Path $path -Recurse | ForEach-Object {
$originalName = $_.Name
if ($_.PSIsContainer) {
"Folder`t$($_.FullName)`t$originalName`t$originalName"
} else {
"File`t$($_.FullName)`t$originalName`t$originalName"
}
}
}
Get-FileFolderList -path $rootFolder | Out-File $outputFile
Write-Host "The file list has been successfully created at $outputFile"
This script creates a tab separated (delimited) file with four columns:
- text denoting whether the data in the row refers to a file or a folder
- the full path, including the name, of the files and folders in the project
- the name of the file or folder – intended to be the source language
- also the name of the file or folder – intended to become the translation of column #3
Script #2: Rename all the files and folders in the project
The script looks like this:
# Prompt for the path to the translated text file
$translatedFilePath = Read-Host "Please enter the full path to the translated text file (filelist.txt)"
# Load the content from the translation file
$content = Get-Content -Path $translatedFilePath
# Sort items by their depth in descending order
$sortedContent = $content | Sort-Object {($_ -split "`t")[1].Split('\').Length} -Descending
foreach ($line in $sortedContent) {
$parts = $line -split "`t"
$type = $parts[0]
$fullPath = $parts[1]
$newName = $parts[3]
if (Test-Path $fullPath) {
# Construct the new path based on the new name
$parentPath = Split-Path -Path $fullPath
$newFullPath = Join-Path -Path $parentPath -ChildPath $newName
try {
Rename-Item -Path $fullPath -NewName $newName
Write-Host "Successfully renamed $type at '$fullPath' to '$newName'."
} catch {
Write-Warning "Failed to rename $type at '$fullPath' to '$newName': $_"
}
} else {
Write-Warning "Could not find $type at path: $fullPath"
}
}
This script loads the tab separated file into memory and then sorts the rows in descending order based on the depth of the path (the number of subfolders indicated by the path). Once it’s done that it replaces the name of each folder, and then file with the translated content from the fourth column.
The way it works in terms of process would be this:
- run the first script
- you will be prompted for the path to the root folder for the project (the one containing all the files and folders)
- the tab separated file (filelist.txt) is created
- translate the filelist.txt so that the fourth column contains the translated names (you could add this back into the overall Trados Studio project as an additional file at the end)
- run the second script
- you will be prompted for the filelist.txt (now translated)
- the script reads from the file and replaces all the names with the translated versions
You can find a video of the whole process in the ideas post in the community, but I reproduced it below for convenience:
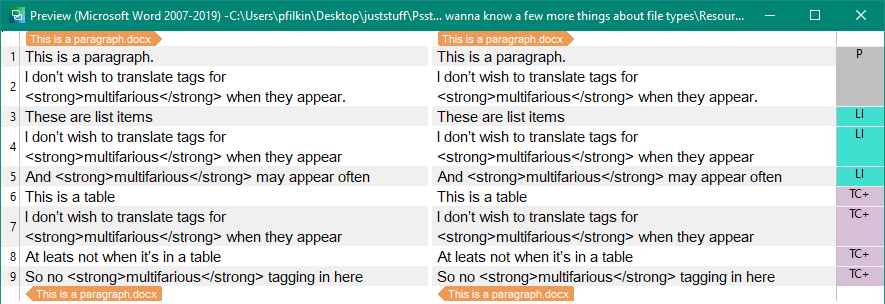
I didn’t mention the Trados Studio part so I’ll cover that here, but first let’s take a look at the filelist.txt in Rons Data Edit:
![A screenshot of a CSV file opened in Rons Data Edit, with 4 columns and several rows visible. Column 00 contains file types like 'File' and 'Folder'. Column 01 has paths to various folders and files on a Windows system. Column 02 lists document titles, such as 'Release Planning' and 'Development Tracking'. Column 03 shows the same titles translated into Chinese characters.]()
You’ll note that the Chinese is already translated and this is because I can easily copy the fourth column (called Column 03 because I didn’t use a header row) into an MT provider, in this case Google Translate, then copy/paste the translated text back. Takes seconds and now I can set up Trados Studio like this:
![A screenshot of the filetype settings for importing a 'Tab Delimited Text' file into Trados Studio. The relevant options include selecting the delimiter, specifying the source and translation columns, and additional settings like extracting comments as structure information, excluding certain lines, handling existing translations, and the process for handling files not matching formatting requirements. In this context, the filetype is set up to consider the third column as the source text and the fourth column as the translated text, with the first column as comments.]()
The advantage being when I open this for translation I have the file ready translated for me to post-edit against the Translation Memory and Termbase I used for the project, so my context is good, and whatever other resources I decide would be useful to complete the work
![The Trados Studio Editor View showing a Translation Memory being used to validate the translations, the DSI Viewer plugin is installed to see the comments as context as I work.]()
It’s funny how this article on the ever so simple CSV file format turned into one of the longest articles I have ever written! If you’re still with me I hope you found it interesting, and perhaps Rons Data Edit is a tool that’ll make its way into your armoury too!
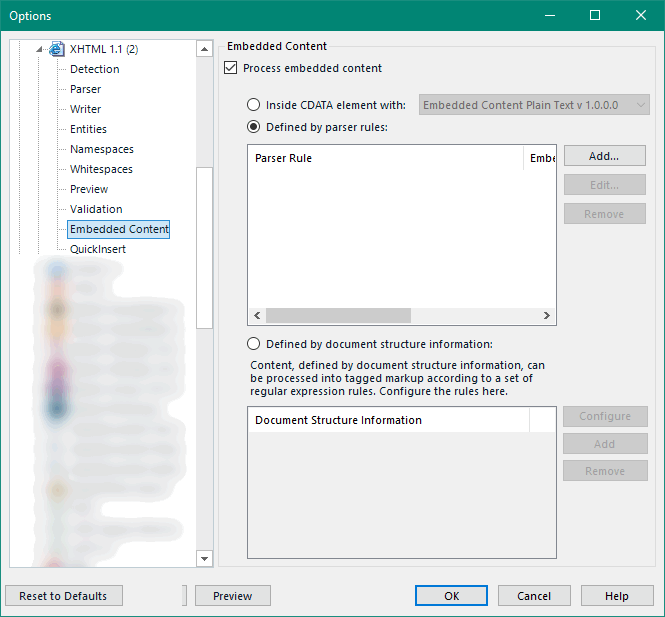
 When we released the new Trados 2021 last week I fully intended to make my first article, after the summary of the release notes, to be something based around the new appstore integration. The number of issues we are seeing with this release are very low which is a good thing, but nonetheless I feel compelled to tackle one thing first that has come up a little in the forums. It relates to some changes made to improve the product for the many.
When we released the new Trados 2021 last week I fully intended to make my first article, after the summary of the release notes, to be something based around the new appstore integration. The number of issues we are seeing with this release are very low which is a good thing, but nonetheless I feel compelled to tackle one thing first that has come up a little in the forums. It relates to some changes made to improve the product for the many.









 I wrote
I wrote 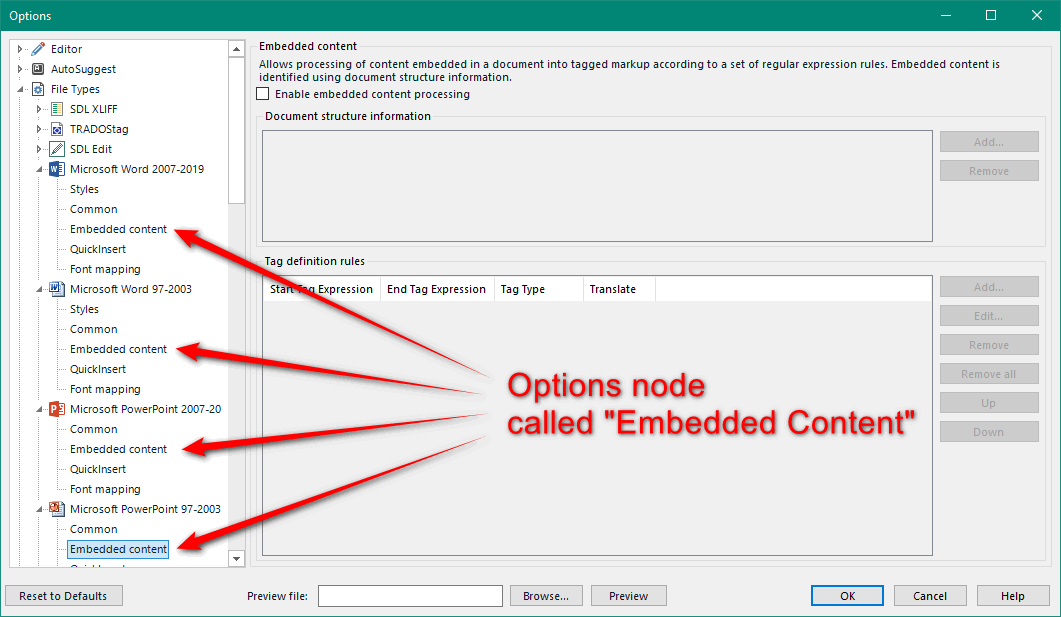






 I was compelled to make a return to a previous theme around Marvel Comics because it’s the only way I can do justice to the amazing work the RWS AppStore team carry out on a daily basis. There are some things you just can’t wait to get up in the morning for, and for me, one of these things is being able to work with this team on a daily basis. The first meeting of every day for me is with this team and what a fantastic way to start the day it is! But as you’ll see the hero of this story is probably a Honey Badger!
I was compelled to make a return to a previous theme around Marvel Comics because it’s the only way I can do justice to the amazing work the RWS AppStore team carry out on a daily basis. There are some things you just can’t wait to get up in the morning for, and for me, one of these things is being able to work with this team on a daily basis. The first meeting of every day for me is with this team and what a fantastic way to start the day it is! But as you’ll see the hero of this story is probably a Honey Badger!


















 Continuing the theme of how to make use of AI technologies to help with the more technical nature of localization I thought I could revisit
Continuing the theme of how to make use of AI technologies to help with the more technical nature of localization I thought I could revisit 







 As I’m getting lost in my own thoughts around just what to talk about next with regard to AI technologies and in particular ChatGPT… and as I’m pondering about the effect this is going to have on our industry I recalled a couple of questions around the use of XPath in the community. One of these questions was yesterday and it related to how to use XPath to extract one of the languages in a TMX file using the XML filetype in Trados Studio. Not a particularly tricky thing to do, and I imagined the user was just editing the content or maybe changing the language pair by translating one of the languages into something else, or something like that. But what struck me was
As I’m getting lost in my own thoughts around just what to talk about next with regard to AI technologies and in particular ChatGPT… and as I’m pondering about the effect this is going to have on our industry I recalled a couple of questions around the use of XPath in the community. One of these questions was yesterday and it related to how to use XPath to extract one of the languages in a TMX file using the XML filetype in Trados Studio. Not a particularly tricky thing to do, and I imagined the user was just editing the content or maybe changing the language pair by translating one of the languages into something else, or something like that. But what struck me was 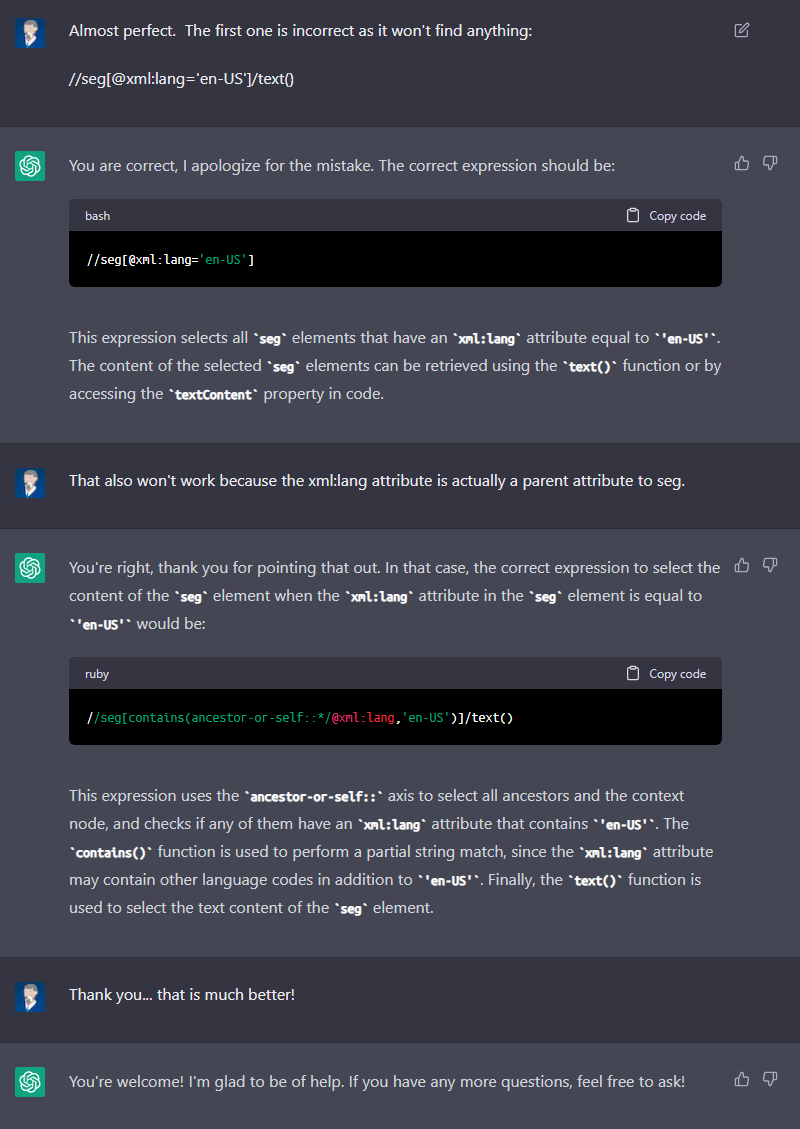

 Localization engineers are the miracle workers behind the scenes of localization workflows, and without them many of the projects we see couldn’t happen. The skillsets they possess go far beyond the sort of things that most translators know how to do, and often require the ability to code. I’ve already
Localization engineers are the miracle workers behind the scenes of localization workflows, and without them many of the projects we see couldn’t happen. The skillsets they possess go far beyond the sort of things that most translators know how to do, and often require the ability to code. I’ve already 










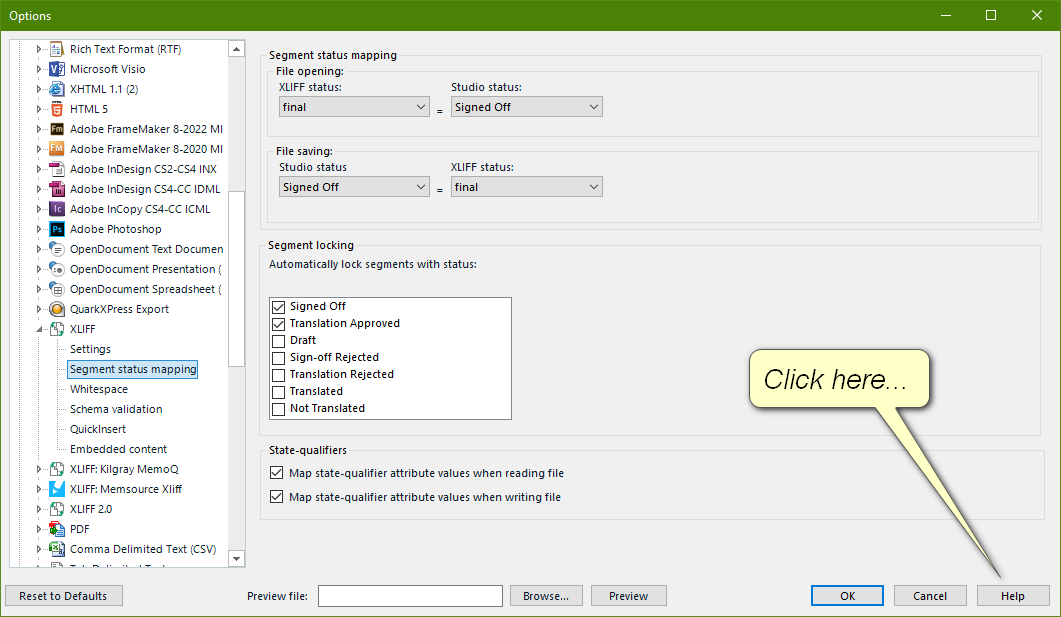



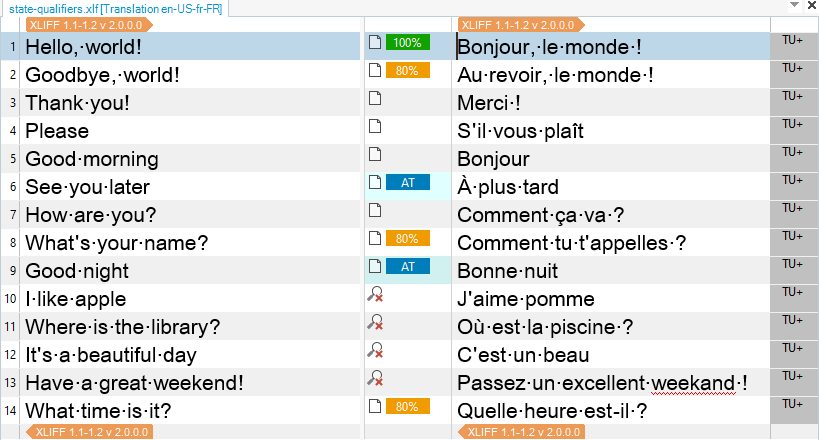

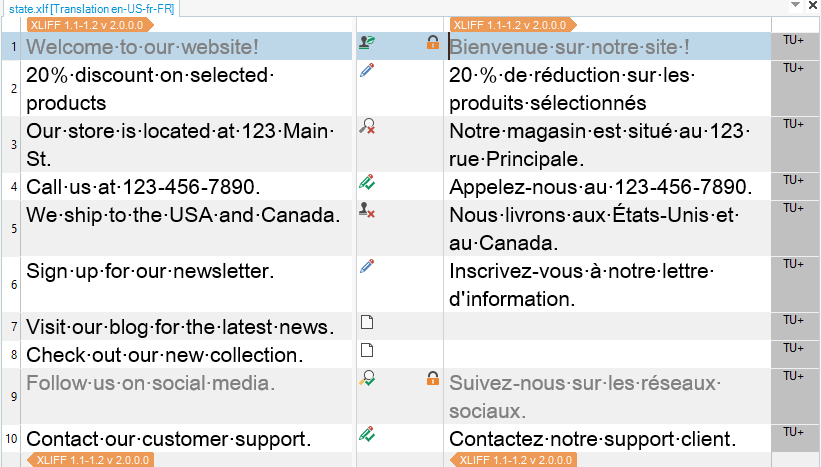

 Whilst I would definitely not claim to be an expert, writing this blog has allowed me to learn a reasonable amount about XML over the years. Most of the articles I’ve written have been about explaining how to manage the many amazing features in the filetypes that are supported by Trados Studio… and of course how to deal with the many changes over the years as the filetypes have become more and more sophisticated catering for the demands of our customers and the changes in the technologies applied to XML in general. The result of these changes has led to some… let’s say… less than user friendly interfaces and features and you’d certainly be forgiven if you thought things were becoming a little chaotic!
Whilst I would definitely not claim to be an expert, writing this blog has allowed me to learn a reasonable amount about XML over the years. Most of the articles I’ve written have been about explaining how to manage the many amazing features in the filetypes that are supported by Trados Studio… and of course how to deal with the many changes over the years as the filetypes have become more and more sophisticated catering for the demands of our customers and the changes in the technologies applied to XML in general. The result of these changes has led to some… let’s say… less than user friendly interfaces and features and you’d certainly be forgiven if you thought things were becoming a little chaotic!













 CSV, or files with “comma separated values”, is a simple format that everyone should be able to handle. Certainly you’d think so except nothing is ever that straightforward and if you’ve ever spent time trying to work with these files and having to deal with all the problems inherent to this format then you’ll know exactly what I’m talking about. In our industry, localization, the number of problems can even increase because we also have to deal with converting the content from one language to another. I also wondered if there is a standard for CSV and the closest things to one is more of a recommendation, called
CSV, or files with “comma separated values”, is a simple format that everyone should be able to handle. Certainly you’d think so except nothing is ever that straightforward and if you’ve ever spent time trying to work with these files and having to deal with all the problems inherent to this format then you’ll know exactly what I’m talking about. In our industry, localization, the number of problems can even increase because we also have to deal with converting the content from one language to another. I also wondered if there is a standard for CSV and the closest things to one is more of a recommendation, called 













